レガシーシステムの保守や刷新を検討している経営層やIT担当者の方に、まず知っておいていただきたいことがあります。それは「レガシーシステムは単なる古いシステムではない」という事実です。そこには、止められないミッションクリティカルな業務、膨大な暗黙知、そして現場でしか分からない運用ノウハウが詰まっています。
私は1994年から1998年まで、上下水道プラント監視システムの開発・保守に40名規模のチームでPG/SEとして携わりました。3年7ヶ月という期間は、システムの保守において「一通りの季節を何度も経験する」という意味で、非常に重要な長さだったと今では思います。この経験が、私のIT人生30年の原点になりました。
当時のシステムはCOBOLで実装され、24時間365日の監視が求められ、物理的なセンサーやポンプと直接連携していました。一つの障害が市民生活に直結する、まさにミッションクリティカルな現場でした。
第1部:レガシーシステム保守の現場で見た5つの真実
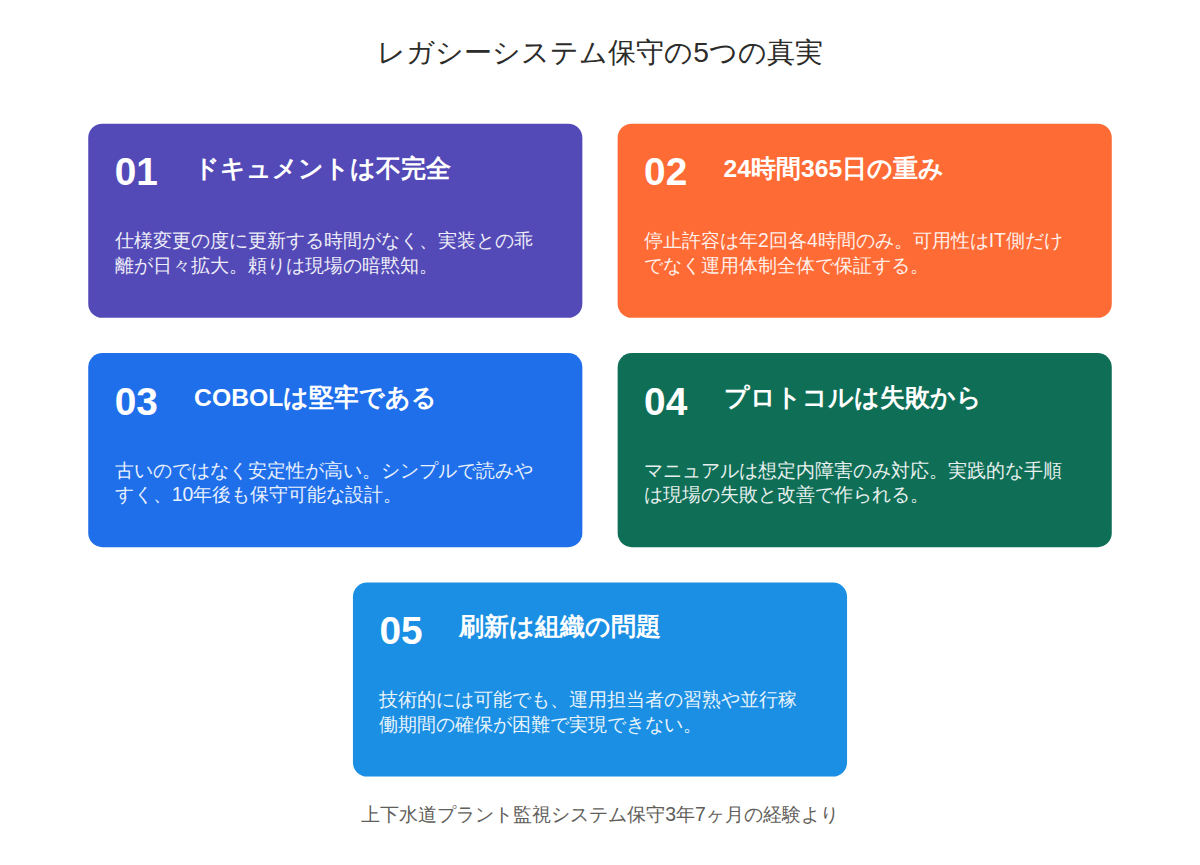
真実1:ドキュメントは常に「不完全」だった
プラント監視システムの保守を始めて最初に驚いたのは、ドキュメントと実際の動作が一致しないことでした。設計書には「ポンプAが停止したらポンプBに自動切替」と書いてありますが、実際には「水位が一定以下の場合は切替しない」という条件が隠れていました。この条件はどこにも書かれていません。
なぜこんなことが起きるのか。答えは単純で、「仕様変更の度にドキュメントを更新する時間がなかった」からです。上下水道という公共インフラは、季節や気象条件によって想定外の事態が頻繁に起きます。台風で急激に水位が上がる、冬場の凍結でセンサーが誤作動する、夏場の渇水で通常とは異なる運転モードにする必要がある。
こうした事態に対応するため、現場では「とりあえず動くように」修正を加え続けます。その修正履歴がドキュメントに反映されないまま、次の修正が入る。こうして、ドキュメントと実装の乖離は日々広がっていきました。
私たちが本当に頼りにしていたのは、ドキュメントではなく「システムを10年見てきたベテラン技術者の記憶」でした。彼らは「このアラームが出たら、まずこのログを見る」「この時間帯にこのエラーが出るのは、あの設備の癖」といった暗黙知を持っていました。
真実2:24時間365日稼働の重みは体感しないと分からない
「24時間365日稼働」という言葉は、IT業界では当たり前のように使われます。しかし、その重みを本当に理解している人は少ないと思います。
プラント監視システムでは、システム停止が許されるのは年に2回、各4時間のメンテナンス時間だけでした。それ以外の時間は、どんな理由があっても止められません。「明日の朝まで待って」という選択肢は存在しないのです。
ある冬の深夜2時、私は障害対応で現場に呼び出されました。気温がマイナス5度まで下がり、屋外に設置されたセンサーケーブルが凍結して断線したのです。システムログには「センサーA応答なし」というエラーが延々と記録されていました。
問題は、このセンサーが水位監視の要だったことです。センサーが機能しない状態では、水位の異常を検知できません。自動制御を停止し、職員が目視で水位を確認しながら手動でポンプを操作する、という緊急体制に切り替えざるを得ませんでした。
私のキャリアの原点は、1994年から1998年にかけての上下水道プラント監視システムの開発・保守プロジェクトでした。PG/SEとして3年7ヶ月、私のキャリアで最長の案件です。体制は40名でした。COBOL実装、24時間365日監視という厳格な要件。深夜に水道局から連絡が入って対応に駆けつけたこともあります。物理機器(センサー、PLC等)との連携が多く、純粋なソフトウェアエンジニアとしてだけでなく、ハードウェアの知識も求められました。障害時の対応プロトコルは、命のライフラインに関わるため非常に厳格で、エスカレーションフローを徹底的に整備しました。今振り返ると、当時のレガシーアーキテクチャは現代のクラウド監視ツールの考え方と本質的には変わらない。ただ、ツールが進化した分、現代のエンジニアは私たちの時代の苦労を知らないままに恩恵を受けているとも感じます。
この経験から学んだのは、「システムの可用性は、IT側だけでは保証できない」という事実です。物理機器の保守、現場の運用体制、バックアップ手順、そしてシステム障害時の代替手段。これらすべてが揃って初めて、24時間365日の稼働が実現できます。
真実3:COBOLは「古い」のではなく「堅牢」だった
COBOLというと、多くの人が「古い言語」「時代遅れ」というイメージを持っています。私も最初はそう思っていました。しかし、3年以上保守を続けて、考えが変わりました。
プラント監視システムのCOBOLコードは、驚くほどシンプルで読みやすいものでした。変数名は「SUII-JOUGEN(水位上限)」「PONPU-A-JOUTAI(ポンプA状態)」のように日本語をローマ字表記したもので、ロジックも直線的です。「IF水位上限超過 THEN ポンプ起動」という具合に、業務ロジックがそのままコードになっています。
現代の言語のように、オブジェクト指向や関数型プログラミングのような複雑な概念はありません。だからこそ、10年後、20年後にそのコードを見る技術者が、容易に理解できるのです。
また、COBOLで書かれたシステムは、驚くほど安定していました。私が担当した3年7ヶ月の間、COBOLのランタイムエラーでシステムが停止したことは一度もありませんでした。問題が起きるのは、常に外部要因(ハードウェア障害、通信エラー、センサー故障)でした。
COBOLが今でも金融機関や公共インフラで使われ続けているのは、単に「移行コストが高いから」だけではありません。「実績があり、安定していて、保守しやすい」という、システムにとって最も重要な特性を持っているからです。
真実4:障害対応プロトコルは「現場の失敗」から生まれる
プロジェクト開始当初、私たちには立派な「障害対応マニュアル」がありました。A4サイズで50ページ以上、あらゆる障害パターンと対応手順が記載されていました。しかし、実際の障害対応では、このマニュアルはほとんど役に立ちませんでした。
理由は単純です。マニュアルに書かれているのは「想定された障害」であり、実際に起きるのは「想定外の障害」だからです。
ある夏の午後、システムが突然、大量のアラートを発し始めました。画面には「ポンプB過負荷」「流量計C異常」「水位センサーD応答遅延」など、10以上のアラートが同時に表示されています。マニュアルを見ても、これらが同時に発生する状況は想定されていません。
現場に駆けつけると、原因は意外なところにありました。近隣で行われていた工事により、電源系統に瞬間的なノイズが発生し、複数のセンサーが同時に誤作動したのです。個々のセンサーは異常を検知しましたが、それらは独立した障害ではなく、一つの根本原因から派生したものでした。
この経験を経て、私たちは障害対応マニュアルを大幅に改訂しました。個々の障害パターンだけでなく、「複数アラートが同時発生した場合の優先順位判断」「根本原因を特定するための確認手順」「現場とIT部門の連携プロトコル」といった、実践的な内容を追加したのです。
本当に機能する障害対応プロトコルは、会議室で考えたものではなく、現場で失敗と改善を繰り返しながら作り上げていくものだと学びました。
真実5:システム刷新は「技術の問題」ではなく「組織の問題」
プロジェクトの後半、「システムの刷新」が検討されました。COBOLからC言語への移行、オープン系システムへの転換、GUIの導入など、技術的には魅力的な提案でした。
しかし、刷新プロジェクトは結局、見送られました。理由は「技術的な困難」ではなく、「組織的な困難」でした。
現場の運用担当者は、長年使い慣れたシステムの操作に習熟しています。「このボタンを押すと、ポンプが起動する」「この画面で水位を確認する」といった操作は、体に染み付いています。新しいGUIシステムに移行すると、これらの操作方法がすべて変わります。
さらに、システム刷新には「移行期間」が必要です。新旧システムを並行稼働させ、徐々に移行していく。しかし、24時間365日稼働のプラント監視システムで、どうやって並行稼働期間を設けるのか。旧システムと新システムで監視結果が異なった場合、どちらを信用するのか。
こうした問いに対する明確な答えがないまま、刷新プロジェクトは「時期尚早」という結論に至りました。技術的には可能でも、組織的・運用的に実現できない。これが、レガシーシステムが刷新されない本当の理由なんですよね。
第2部:なぜレガシーシステムの保守は困難なのか
技術的負債の本質は「時間との戦い」
レガシーシステムがなぜ保守困難になるのか。よく言われるのは「技術的負債」という言葉です。しかし、この言葉は本質を表現しきれていないと私は思います。
本当の問題は、「システムの変化速度」と「ドキュメント更新速度」の乖離です。システムは現場の要求に応じて日々変化します。しかし、その変化を正確にドキュメント化する時間は、常に不足しています。
プラント監視システムでは、年間50件以上の仕様変更がありました。1週間に1件のペースです。それぞれの変更は小さなものですが、設計書を更新し、テスト仕様書を改訂し、運用マニュアルを修正するには、変更作業の2倍以上の時間がかかります。
結果として、「動くけれど、なぜ動くのか分からない」コードが増えていきます。これが技術的負債の正体です。借金が雪だるま式に増えるように、ドキュメントと実装の乖離は日々拡大していきました。
暗黙知の属人化は構造的な問題
「ベテラン技術者に依存している」という問題も、よく指摘されます。しかし、これは個人の問題ではなく、システム保守の構造的な問題です。
ミッションクリティカルなシステムでは、「マニュアル通りに対応する」だけでは不十分です。システムの挙動、現場の状況、過去の障害事例、これらを総合的に判断して、最適な対応を選択する必要があります。この判断力は、マニュアルからは学べません。実際の障害対応を何度も経験して、初めて身につくものです。
つまり、システムが複雑であればあるほど、稼働期間が長ければ長いほど、暗黙知は蓄積されていきます。そして、その暗黙知を持つ技術者は、組織にとってかけがえのない存在になります。これは避けられない構造なのです。
物理世界との接続が複雑性を生む
プラント監視システムが特に複雑だったのは、物理的な設備と直接連携していたからです。ソフトウェアだけで完結するシステムなら、テスト環境で動作確認ができます。しかし、物理設備との連携は、実機でしか確認できません。
「ポンプを起動するコマンドを送信する」というシンプルな処理でも、実際には多くの要素が絡みます。電気信号の電圧レベル、ケーブルの長さによる遅延、ノイズ対策、ポンプ側の受信回路の特性。これらすべてが、システムの動作に影響します。
さらに、物理設備は経年劣化します。10年前は正常に動作していた処理が、ケーブルの劣化やポンプの摩耗により、突然エラーを起こすようになります。ソフトウェアは変わっていないのに、システムの動作が変わるのです。
この「ソフトウェアとハードウェアの境界領域」の複雑性が、レガシーシステム保守の困難さを何倍にも増幅させていました。
第3部:現代のクラウド・IoT技術で何が変わるのか
監視の概念が根本から変わった
1994年当時、システム監視は「専用機器による専用監視」が当たり前でした。監視用のコンソールは専用のハードウェアで、監視ソフトウェアも専用開発。すべてがオンプレミスで、すべてが個別最適化されていました。
しかし現代では、クラウド型の監視サービスが状況を一変させています。Datadog、Mackerel、Amazon CloudWatchといったサービスを使えば、インフラからアプリケーション、ログまで、統合的に監視できます。
特に重要なのは、「監視設定の標準化」です。かつては「どのメトリクスを監視すべきか」「アラートの閾値をどう設定するか」といった判断を、個別にしていました。しかし、クラウド監視サービスには、業界のベストプラクティスが組み込まれています。初期設定だけで、それなりのレベルの監視が開始できます。
また、「監視データの可視化」も劇的に進化しました。当時は数値の羅列やシンプルなグラフしか表示できませんでしたが、現代のダッシュボードは、複数のメトリクスを組み合わせた洞察を提供します。「CPU使用率が高い時、どのプロセスが原因か」「レスポンス時間の遅延は、どのコンポーネントで発生しているか」といった分析が、リアルタイムで可能です。
IoT連携で物理世界のデータも統合管理
プラント監視システムで最も苦労したのは、「物理センサーとITシステムの連携」でした。当時は、センサーごとに専用の通信プロトコルがあり、変換装置を経由してシステムに取り込んでいました。
現代のIoT技術は、この状況を大きく変えています。センサーからのデータをMQTTやHTTPといった標準プロトコルで送信し、クラウド上で一元管理できます。AWS IoT Core、Azure IoT Hub、Google Cloud IoTといったサービスを使えば、数千・数万のセンサーからのデータを、スケーラブルに処理できます。
特に注目すべきは、「エッジコンピューティング」の進化です。センサー側である程度のデータ処理を行い、異常値だけをクラウドに送信する。これにより、通信量を削減しつつ、リアルタイム性を確保できます。
また、機械学習を活用した「予兆検知」も現実的になっています。過去のセンサーデータから正常動作のパターンを学習し、そこから逸脱した挙動を検知する。これにより、「故障してから対応する」ではなく、「故障する前に対応する」予防保全が可能になります。
ログ管理とトレーサビリティの革新
障害対応で最も時間がかかったのは、「原因の特定」でした。複数のサーバー、複数のアプリケーション、複数の物理機器のログを手作業で照合し、時系列を整理し、因果関係を推測する。この作業に、数時間から数日かかることもありました。
現代のログ管理ツール(Elasticsearch, Splunk, Sumo Logic等)は、この作業を劇的に効率化します。分散した複数のログを一箇所に集約し、タイムスタンプで自動的に整列させ、キーワード検索やフィルタリングが瞬時にできます。
さらに、「分散トレーシング」という技術により、複数のシステムをまたがる処理の流れを可視化できます。「ユーザーのリクエストが、どのサーバーを経由して、どのデータベースにアクセスし、どこで遅延が発生したか」が、一つのタイムラインで表示されます。
これは、システム間の依存関係が複雑な現代のマイクロサービス環境では、不可欠な技術です。かつて数時間かかっていた原因特定が、数分で完了するようになります。
コンテナ化とInfrastructure as Codeによる再現性確保
レガシーシステムで最も困難だったのは、「環境の再現」でした。本番環境とテスト環境で微妙に設定が異なり、「テストでは動いたのに本番で動かない」という事態が頻発しました。
DockerやKubernetesといったコンテナ技術は、この問題を根本から解決します。アプリケーションとその実行環境を一つのパッケージとして管理できるため、「どの環境でも同じように動く」ことが保証されます。
また、TerraformやAnsibleといったInfrastructure as Code(IaC)ツールにより、インフラの設定をコードとして管理できます。「本番環境のサーバー設定」をコードで記述しておけば、いつでも同じ環境を再構築できます。
これは、災害復旧(DR)の観点でも重要です。かつては、障害が発生すると、手順書を見ながら手作業でサーバーを再構築していました。しかし、IaCを使えば、コマンド一つで環境を復元できます。復旧時間が、数日から数時間に短縮されます。
CI/CDによる変更管理の自動化
プラント監視システムでは、ソースコードの変更からデプロイまで、多くの手作業がありました。ソースコードをコンパイルし、テストサーバーにコピーし、動作確認し、本番環境にコピーし、サービスを再起動する。この一連の作業に、半日以上かかることもありました。
CI/CD(継続的インテグレーション/継続的デリバリー)のパイプラインを構築すれば、これらの作業を自動化できます。GitHubやGitLabにコードをプッシュすると、自動的にビルド、テスト、デプロイが実行されます。人的ミスのリスクが大幅に減り、デプロイ頻度を上げられます。
特に重要なのは、「ロールバックの容易さ」です。デプロイ後に問題が見つかった場合、以前のバージョンに瞬時に戻せます。かつては「一度デプロイしたら戻せない」という緊張感がありましたが、現代では「とりあえずデプロイして、問題があれば戻す」という運用が可能です。
実際の移行ステップと現実的な課題
ここまで、現代の技術がいかに優れているかを説明してきました。しかし、レガシーシステムから現代的なシステムへの移行は、技術的には可能でも、現実的には非常に困難です。
まず、「並行稼働期間の確保」が必要です。24時間365日稼働のシステムを止めることはできないため、旧システムを動かしながら新システムを構築し、徐々に切り替えていく必要があります。この期間は、最低でも6ヶ月、複雑なシステムでは2年以上かかります。
次に、「現場の運用トレーニング」が不可欠です。新しいダッシュボード、新しいアラート通知、新しい操作手順。これらを現場担当者が習熟するには、時間がかかります。特に、長年旧システムを使ってきたベテラン担当者ほど、新システムへの適応に時間がかかる傾向があります。
また、「データ移行」も大きな課題です。過去10年、20年分の監視データや設定情報を、新システムに移行する必要があります。データ形式が異なるため、変換プログラムを作成し、データの整合性を確認し、という作業が必要です。
現実的な移行計画としては、以下のステップを推奨します。
- 第1段階(3ヶ月):監視データの並行収集。旧システムと新システムで同じデータを監視し、結果を比較検証
- 第2段階(3ヶ月):新システムでの監視開始。ただし、アラート通知は旧システムのまま
- 第3段階(3ヶ月):新システムへのアラート通知切替。現場担当者のトレーニング実施
- 第4段階(3ヶ月):旧システムのバックアップモードへの移行。新システムをメインとし、旧システムは緊急時のバックアップとして維持
- 第5段階(6ヶ月):旧システムの完全停止。ただし、この判断は慎重に行う
最低でも18ヶ月の移行期間を見込む必要があります。経営層は「数ヶ月で移行できる」と期待しがちですが、ミッションクリティカルなシステムの移行は、それほど単純ではありません。
具体的なツール紹介
Datadog:統合監視プラットフォームの決定版
Datadogは、インフラ・アプリケーション・ログを統合的に監視できるSaaS型監視サービスです。プラント監視のような複雑なシステムでも、包括的な可視化が可能です。
便利な機能
- 700以上のインテグレーション:AWS、Azure、Google Cloudといったクラウドサービスから、MySQL、PostgreSQLなどのデータベース、さらにはIoTデバイスまで、幅広く対応
- リアルタイムダッシュボード:複数のメトリクスを組み合わせたダッシュボードを、ドラッグ&ドロップで簡単に作成
- APM(Application Performance Monitoring):アプリケーションの内部動作を可視化し、ボトルネックを特定
- 分散トレーシング:マイクロサービス間のリクエストの流れを追跡
- ログ管理:数百万件のログを瞬時に検索・分析
使いこなしの難しさ
Datadogは機能が非常に豊富なため、「どこから手をつければいいか分からない」という声をよく聞きます。初期設定だけで数十時間かかることもあります。
特に、アラート設定の最適化は困難です。閾値を厳しくしすぎると、アラートが頻発して「オオカミ少年」状態になります。逆に、閾値を緩くしすぎると、本当の異常を見逃します。適切なバランスを見つけるには、実際に運用しながら調整を繰り返す必要があります。
また、コストが比較的高いという点も課題です。監視対象のホスト数や取り込むログ量に応じて課金されるため、大規模システムでは月額数十万円以上になることもあります。
Mackerel:日本企業に最適化された監視サービス
Mackerelは、日本のはてな社が提供する監視サービスです。日本語ドキュメントが充実しており、日本の商習慣に合わせた料金体系やサポート体制が特徴です。
便利な機能
- シンプルで直感的なUI:日本語で設計されているため、英語が苦手な現場担当者でも使いやすい
- サービスメトリック:「Webサーバー」「DBサーバー」「APサーバー」といった役割ごとにメトリクスを整理できる
- チェック監視:外形監視やプロセス監視など、基本的な監視機能が標準搭載
- 異常検知:機械学習により、通常パターンからの逸脱を自動検知
- OpsgenieやPagerDutyとの連携:アラートを適切な担当者にエスカレーション
使いこなしの難しさ
Mackerelは、Datadogに比べると機能がシンプルです。これは利点でもあり、欠点でもあります。基本的な監視には十分ですが、複雑な分析や高度なカスタマイズが必要な場合、機能不足を感じることがあります。
また、インテグレーションの数がDatadogほど多くありません。特殊なミドルウェアやIoTデバイスとの連携では、カスタムプラグインを自作する必要が出てきます。これには、それなりのプログラミングスキルが必要です。
Amazon CloudWatch:AWS環境なら第一選択肢
AWS上でシステムを構築している場合、CloudWatchは最も自然な選択肢です。AWSの各サービスと深く統合されており、追加設定なしで基本的な監視が開始できます。
便利な機能
- AWSサービスとのネイティブ統合:EC2、RDS、Lambda、S3など、すべてのAWSサービスのメトリクスを自動収集
- カスタムメトリクス:アプリケーション固有のメトリクスを送信し、監視可能
- CloudWatch Logs:ログの収集・検索・分析が可能
- CloudWatch Alarms:閾値ベースのアラートを簡単に設定
- CloudWatch Dashboards:カスタムダッシュボードを作成し、重要なメトリクスを一覧表示
使いこなしの難しさ
CloudWatchは、DatadogやMackerelに比べると、UIが洗練されていません。ダッシュボードの作成やアラート設定が、やや煩雑に感じられます。
また、AWS以外のリソース(オンプレミスサーバー、他社クラウド)を監視する場合、追加の設定やエージェントのインストールが必要です。マルチクラウド環境では、CloudWatchだけでは不十分な場合があります。
ログの保存期間とコストも注意が必要です。デフォルトでは、ログは無期限に保存されますが、保存量に応じて課金されます。大量のログを長期間保存すると、予想外のコストがかかることがあります。ログのライフサイクル管理(古いログは自動削除、または低コストなS3に移動)を適切に設定する必要があります。
Azure Monitor:Microsoft環境との統合に強み
Azure Monitor(旧Operations Management Suite)は、Azureのクラウド監視サービスです。Windows Server、Active Directory、Microsoft SQL Serverなど、Microsoft製品との親和性が高いのが特徴です。
便利な機能
- Application Insights:ASP.NETアプリケーションのパフォーマンスを詳細に監視
- Log Analytics:強力なクエリ言語(KQL)により、ログを柔軟に分析
- Workbooks:Excelライクな操作でレポートを作成
- Autoscale:メトリクスに基づいて、リソースを自動的にスケール
使いこなしの難しさ
Azure Monitorの最大の課題は、「複雑な料金体系」です。データの取り込み量、保存期間、クエリの実行回数など、複数の要素で課金されます。事前にコストを正確に見積もることが困難で、「使ってみたら予想以上に高額だった」という事態が起こりやすいです。
また、KQL(Kusto Query Language)という独自のクエリ言語を習得する必要があります。SQLに似ていますが、微妙に文法が異なるため、学習コストがかかります。
まとめ:レガシーシステム保守から学んだ本質
3年7ヶ月のプラント監視システム保守を通じて、私が学んだ最も重要なことは、「システムは人と組織の一部である」という事実です。
レガシーシステムは、技術的に古いから保守が困難なのではありません。そのシステムに依存した業務プロセス、そのシステムを知り尽くした人々、そのシステムを前提とした組織構造。これらすべてが絡み合って、変革を困難にしているのです。
現代のクラウド・IoT技術は、確かに素晴らしいものです。1990年代には不可能だったことが、今では簡単に実現できます。しかし、技術だけでは何も解決しません。新しい技術を導入するには、組織の理解、現場の協力、そして十分な時間が必要です。
レガシーシステムの刷新を検討している経営層・IT担当者の方に、最後にお伝えしたいことがあります。「完璧な移行計画」など存在しません。重要なのは、現場の声を聞き、小さく始め、失敗から学びながら進めることです。
1994年から1998年の経験は、私のキャリアの原点です。あの時の緊張感、責任の重さ、そして現場で学んだ知恵は、30年経った今でも、私の判断基準の核になっています。
レガシーシステムの保守は、決して華やかな仕事ではありません。しかし、社会のインフラを支える、極めて重要な仕事です。この記事が、同じ道を歩む方々の参考になれば幸いです。


コメント