データ連携プロジェクトは、一見シンプルに見えて実は落とし穴だらけです。私は2005年から2006年にかけて、ASTERIAを使った大規模データ連携プロジェクトに1年10ヶ月間携わり、30名規模のチームでSE兼プロジェクトリーダーとして5案件以上の顧客データ連携を手がけました。その中で、何度も同じパターンの失敗に直面し、時には本番障害まで引き起こしてしまいました。
システム間でデータをやり取りするだけなのに、なぜこんなに難しいのか。当時は必死で対応していましたが、今振り返ると、失敗には明確なパターンがあったことがわかります。この記事では、私が現場で痛感した「データ連携が失敗する3つのパターン」と、その教訓から学んだ対策、そして現代のiPaaSツールではどう改善されているのかを、実務者の視点から解説します。
第1部:データ連携プロジェクトの現場で起きていたこと
「データ連携なんて簡単でしょ?」という幻想
プロジェクトの立ち上げ時、データ連携は「技術的に枯れている領域」として扱われがちです。確かに、AシステムからBシステムへCSVファイルを渡すだけなら、一見簡単そうに見えます。しかし、実際の現場ではこの認識が大きな誤解を生む原因になるんですよね。
私が担当したプロジェクトでも、当初は「既存システムからデータを抽出して、新システムに流し込むだけ」という説明で始まりました。経営層も「それなら3ヶ月もあれば十分だろう」という認識でした。しかし蓋を開けてみると、1年10ヶ月という長期プロジェクトになり、その間に数え切れないほどのトラブルに見舞われました。
5案件を通じて見えてきた共通の失敗パターン
複数の顧客案件を担当する中で、不思議なことに気づきました。業種も規模も異なる顧客なのに、データ連携で発生する問題はほぼ同じパターンなのです。最初の案件で経験した失敗を、2案件目、3案件目でも繰り返してしまう。チーム内で情報共有していたはずなのに、なぜか同じ轍を踏んでしまうんです。
当時は「なぜこんなに似たような問題ばかり起きるのか」と不思議に思っていましたが、今ならその理由がわかります。データ連携の失敗は、技術的な問題ではなく、むしろコミュニケーションと設計思想の問題だったのです。
パターン1:データ仕様書が顧客とベンダーで食い違う
最も頻繁に、そして最も深刻な影響を及ぼしたのが、この「仕様書の食い違い」問題でした。具体的には、顧客側が用意したデータ仕様書と、実際にシステムから出力されるデータの内容が一致しないというケースです。
ある金融系の案件では、顧客から「顧客マスタのデータ仕様書」として20項目のExcelファイルを受け取りました。私たちはその仕様書をもとにASTERIAのフローを設計し、テスト環境で動作確認も完了させました。ところが本番データを流してみると、仕様書にない項目が5つも追加されており、逆に仕様書にある項目のうち2つが実際には存在しませんでした。
さらに問題だったのは、データ型の違いです。仕様書では「数値型」と記載されていた「金額」フィールドが、実際には「カンマ区切りの文字列」で格納されていたのです。つまり「1000000」ではなく「1,000,000」という形式です。これに気づかずに処理を進めた結果、金額計算でエラーが多発し、連携処理が途中で止まってしまいました。
2005年から2006年にかけて、私はSE/PLとしてデータ連携をASTERIAで実装するプロジェクトに1年10ヶ月従事しました。体制は30名、複数の顧客向けに5案件以上のデータ移行を手がけました。失敗パターンのうち、最も印象に残っているのは『データ仕様書が顧客とベンダーで微妙に食い違っていた』ケースです。プロジェクト中盤のテストフェーズで、想定外のデータパターンが本番データから次々と発見され、対応に2ヶ月かかりました。文字コード問題もよく起きました。Shift_JISとUTF-8の混在で本番障害が発生し、休日対応に駆り出されたことも。連携パターンが増えるとメンテ不能になるリスクも経験しました。教訓は、連携設計の標準化と命名規則を最初に固めること。現代のiPaaSツールでもこの原則は変わりません。
この問題の根本原因は、顧客側のシステム担当者と実際の基幹システムを管理している部門が別だったことです。システム担当者は「こうあるべき」という理想の仕様書を作成していましたが、実際の基幹システムは過去の開発経緯で仕様書とは異なる実装になっていました。そしてその乖離について、誰も正確に把握していなかったのです。
パターン2:文字コード問題で本番障害が発生する
2つ目の失敗パターンは、文字コードに関する問題でした。これは本番稼働後に障害として顕在化することが多く、影響範囲も広くなりがちです。
製造業の顧客案件で、販売管理システムから会計システムへ売上データを連携する処理を実装していました。テスト環境では何の問題もなく動作していたのですが、本番稼働の初日、突然データ連携が止まってしまいました。調査してみると、ある取引先名に含まれていた特殊文字(「髙」という字体の「高」)が原因で、文字コード変換時にエラーが発生していたのです。
送信側のシステムはShift_JISで動作しており、受信側のシステムはUTF-8でした。ASTERIAでは文字コード変換機能があるため、設計時には「これで問題ない」と判断していました。しかし、Shift_JISにしか存在しない文字や、UTF-8では表現できない外字が含まれていると、変換時にデータが欠損したり、エラーで処理が止まったりすることがあります。
さらに厄介だったのは、この問題がテスト段階では発見できなかったことです。テストデータとして顧客から提供されたサンプルには、たまたまこうした特殊文字が含まれていませんでした。本番データには数万件の取引先情報があり、その中のわずか数件に特殊文字が含まれていただけなのですが、連携処理はそこで止まってしまいました。
この障害対応には丸2日かかりました。エラーログから原因を特定し、該当する文字の変換ルールを追加し、過去に遡ってデータを補正する必要があったためです。しかも、同様の問題が他の連携処理でも発生する可能性があるため、全ての連携フローを見直すことになりました。
パターン3:連携パターンが増えてメンテナンス不能に陥る
3つ目の失敗パターンは、プロジェクトが進むにつれて徐々に深刻化していく「メンテナンス性の悪化」です。これは最も予防が難しく、気づいた時には手遅れになっていることが多い問題でした。
プロジェクト開始時、私たちは5つのシステム間でデータ連携を行う予定でした。ところが実際には、要件追加や仕様変更により、最終的には12システム間で30以上の連携パターンを実装することになりました。問題は、それぞれの連携処理を個別に設計・実装していったことです。
ASTERIAでは、データ連携の処理を「フロー」という単位で作成します。最初のうちは、各フローに「受注データ連携_販売to会計」のような分かりやすい名前をつけていました。しかし案件が増えるにつれて、命名規則が曖昧になり、「受注_販売会計」「受注データ移行」「受注連携_修正版」といった似たような名前のフローが乱立するようになりました。
さらに深刻だったのは、同じような処理ロジックが複数のフローにコピー&ペーストで実装されていたことです。例えば「日付フォーマット変換」の処理は、ほぼ全ての連携フローで必要でした。最初のフローで実装したロジックを、他のフローにもコピーして使っていたのですが、途中で日付フォーマットの要件が変更になった時、全てのフローを修正しなければならなくなりました。
結果として、どのフローがどのシステム間を連携しているのか、どの処理が共通で使われているのか、誰も全体を把握できない状態になりました。あるフローを修正すると別のフローに影響が出るかもしれない、という恐怖から、誰も既存のフローに手を入れたがらなくなり、結果として新しいフローをどんどん追加するという悪循環に陥りました。
プロジェクト終盤には、フローの総数は50を超えていました。そのうち実際に稼働しているのは30程度で、残りは「もう使っていないと思うけど、確証がないから削除できない」という幽霊フローでした。この状態でのメンテナンスは非常に困難で、軽微な修正に何日もかかるようになっていました。
第2部:なぜこれらの失敗は繰り返されるのか
データ連携が「技術的に簡単」という思い込み
3つの失敗パターンに共通しているのは、データ連携を「技術的に簡単な作業」と見なしてしまう認識の問題です。確かに、技術的には確立された領域ですし、ASTERIAのようなツールを使えば、プログラミングなしでデータ連携を実装できます。しかし、だからといって「誰でも簡単にできる」わけではありません。
データ連携の本質は、異なる思想で設計された複数のシステムの間に橋を架ける作業です。それぞれのシステムには、それぞれの歴史があり、それぞれの制約があります。それを理解せずに表面的な仕様だけで連携を設計すると、必ず問題が起きます。
仕様書の食い違いが起きるのは、「システムの仕様書=システムの実態」という前提が間違っているからです。多くの企業では、基幹システムは何年も前に構築され、その後も継ぎ接ぎで機能追加や修正が重ねられています。当初の設計書は更新されないまま、実際のシステムだけが変化していくため、仕様書と実態の乖離が生じます。
「とりあえず動けばいい」という場当たり的な対応
文字コード問題が本番で発覚するのは、テスト計画が甘いという側面もありますが、より根本的には「とりあえず動作確認できればOK」という姿勢が原因です。テスト環境で正常に動いたから本番も大丈夫だろう、という楽観的な判断をしてしまうわけです。
しかし実際には、本番データには様々な例外的なケースが含まれています。長年蓄積されたマスタデータには、手入力ミスで生まれた全角と半角の混在、過去のシステム移行時に持ち込まれた特殊文字、誰も意味を理解していない謎のコード値などが潜んでいます。こうした「想定外」のデータに対する考慮が不足していると、本番障害につながります。
私自身、当時は「文字コード変換はASTERIAが自動でやってくれるから大丈夫」と考えていました。しかし実際には、自動変換できないケースが存在することを、本番障害という形で思い知らされました。ツールの機能を過信し、例外処理の設計を怠っていたのです。
標準化と命名規則の軽視
メンテナンス不能に陥るのは、プロジェクト開始時に標準化や命名規則の重要性を軽視してしまうからです。「まずは動くものを作ろう」という姿勢は悪くありませんが、それが「後で整理すればいい」という先送りの姿勢につながると危険です。
データ連携プロジェクトは、初期段階では小規模に見えても、必ず拡大していきます。「とりあえずこの2システム間を連携させよう」で始まったプロジェクトが、気づけば10システム以上を巻き込む大規模なものになっている、というのはよくあるパターンです。
そうなった時に、最初から標準化されたアプローチを取っていないと、後から整理するのは非常に困難です。すでに本番稼働している連携処理を止めるわけにはいかないため、新しい標準を適用するのは新規案件だけになり、結果として古い方式と新しい方式が混在する状態が続きます。
私たちのプロジェクトでも、途中で「もっと体系的な命名規則が必要だ」と気づき、新しいルールを策定しました。しかし既存のフローを全て新ルールに従って作り直す時間は取れず、結局は二つの命名規則が混在する状態が最後まで続きました。
「見えない複雑さ」を過小評価する構造
これら3つの失敗パターンに共通するのは、データ連携の「見えない複雑さ」を過小評価してしまうことです。画面開発なら、作った画面を見せれば関係者全員が進捗や問題点を理解できます。しかしデータ連携は、動作結果しか見えません。「データが正しく連携されている」ということは確認できても、その裏でどんな複雑な処理が動いているか、どんなリスクが潜んでいるかは、見ただけではわかりません。
この「見えにくさ」が、データ連携プロジェクトでの失敗を繰り返す根本原因だと私は考えています。問題が見えないから、対策の優先度も上がらない。そして本番障害という形で顕在化して初めて、「こんなに複雑だったのか」と気づくわけです。
第3部:現代のデータ連携で同じ失敗を繰り返さないために
失敗から学んだ3つの教訓と対策
1年10ヶ月のプロジェクトを通じて、私が学んだ最も重要な教訓は「データ連携は技術の問題ではなく、設計とマネジメントの問題である」ということです。どんなに優れたツールを使っても、設計思想が間違っていれば失敗します。逆に言えば、適切な設計とマネジメントがあれば、多くの失敗は防げます。
具体的な対策として、私が今なら必ず実施する3つのポイントを紹介します。
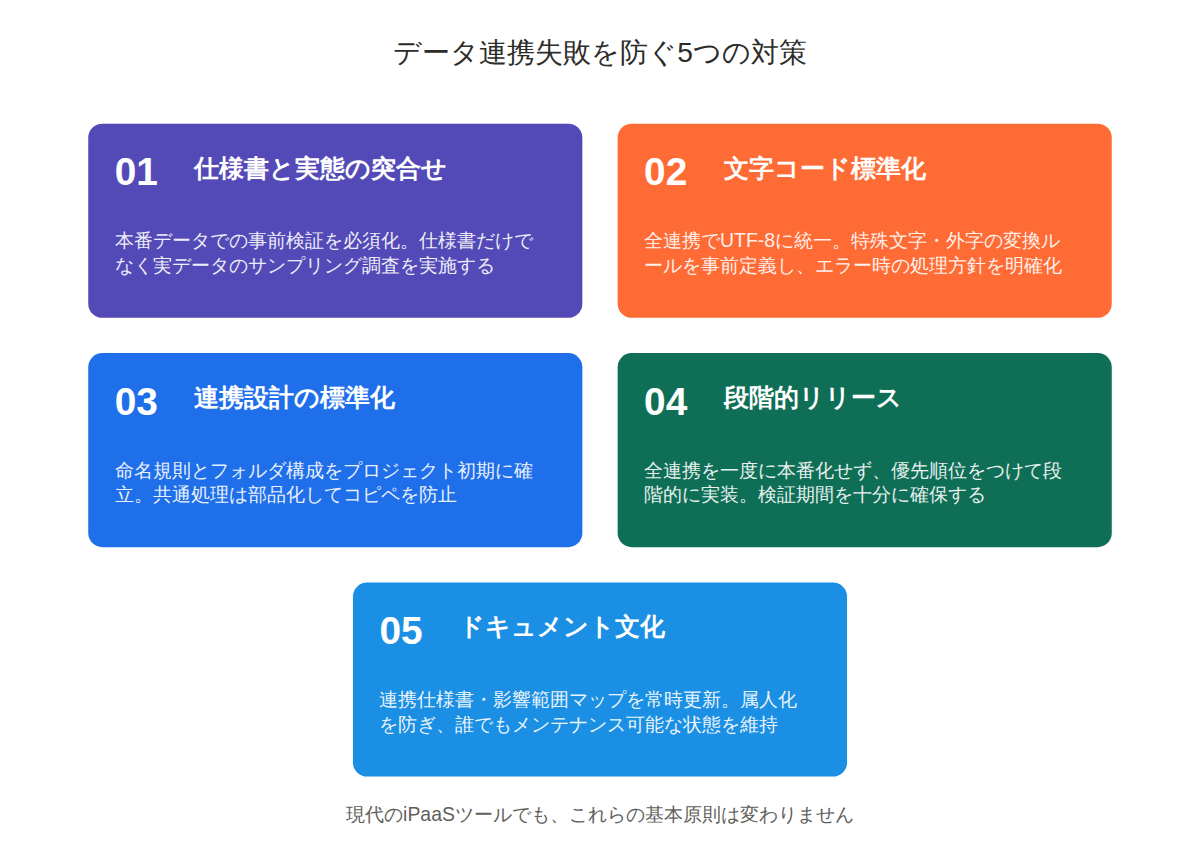
対策1:仕様書を信じない、実データで確認する
顧客から提供される仕様書は、あくまで「参考資料」として扱うべきです。本当の仕様は、実際のシステムから抽出したデータの中にあります。プロジェクト開始時に、必ず本番環境(または本番に近い環境)から実データのサンプルを取得し、仕様書との突合せを行います。
この時、単に項目名やデータ型を確認するだけでは不十分です。実際のデータの中身を見て、以下の点を確認します:
- NULL値や空文字がどの程度含まれているか
- 数値項目に文字が混入していないか
- 日付項目のフォーマットは統一されているか
- コード値の範囲は仕様書通りか
- 文字数制限は守られているか
この確認作業には時間がかかりますが、後から発覚する問題に比べれば、遥かに効率的です。実際、この作業を丁寧に行うことで、仕様書との乖離を事前に発見し、顧客と認識合わせをすることができます。
対策2:文字コード戦略を最初に決める
文字コード問題を防ぐには、プロジェクト全体で統一した文字コード戦略を持つことが重要です。理想的には、全システムをUTF-8で統一することですが、既存システムとの連携がある場合、それは現実的ではありません。
そこで、以下のような戦略を立てます:
- データ連携の内部処理は全てUTF-8で統一する
- 送信側・受信側システムに合わせて入出力時に文字コード変換を行う
- 変換できない文字が出現した場合の処理ルールを事前に決めておく(エラーで止める/代替文字に置換/ログに記録して処理続行、など)
- 外字や機種依存文字のリストを作成し、テストデータに含める
また、顧客の基幹システムで使用されている文字コードと、実際にどんな文字が使われているかを事前調査します。特に人名や地名には要注意です。「髙」「﨑」「德」などの異体字、「①」「㈱」などの機種依存文字が含まれていないか、サンプルデータで確認します。
対策3:連携設計の標準化と命名規則の徹底
メンテナンス性を確保するには、プロジェクト開始時に標準化方針と命名規則を確立し、全メンバーに徹底させることが不可欠です。この「最初の一手間」を惜しむと、後で何倍もの手間がかかることになります。
具体的には、以下のような標準を定めます:
- フロー命名規則:「処理種別_送信元システム_受信先システム_連携データ種別」の形式で統一(例:「DAILY_SALES_ACCOUNT_ORDER」)
- 共通処理の部品化:日付変換、文字コード変換、エラーハンドリングなど、複数のフローで使う処理は必ず共通部品として切り出す
- エラーハンドリングの統一:全てのフローで同じ方式でエラーログを出力し、同じ方式でリトライや通知を行う
- ドキュメントテンプレート:各フローの目的、連携仕様、依存関係を記録するドキュメントのテンプレートを作成し、全フローで使用する
これらの標準を守らせるには、コードレビューの仕組みが有効です。新しいフローを実装したら、必ず別のメンバーがレビューし、標準に準拠しているかを確認します。最初は手間に感じるかもしれませんが、これがプロジェクト後半でのメンテナンス性を大きく左右します。
現代のiPaaSツールが解決できること、できないこと
私が携わった2005〜2006年当時と比べて、現代のデータ連携ツールは大きく進化しています。iPaaS(Integration Platform as a Service)と呼ばれるクラウド型の統合プラットフォームが登場し、データ連携の実装はより容易になりました。しかし、ツールが進化しても解決できない本質的な課題もあります。
現代の主要なiPaaSツールとその特徴を、実務的な視点で見ていきましょう。
ツール1:ASTERIA Warp(アステリア ワープ)
私が使っていたASTERIAの後継製品です。基本的なコンセプトは当時と変わりませんが、クラウド対応が進み、SaaSとの連携機能が大幅に強化されています。
便利な機能:
- GUIベースのフロー設計で、プログラミング不要
- Salesforce、kintone、Sansan等の主要SaaSとの標準アダプタを提供
- REST API、SOAP、FTP、データベース等、多様なプロトコルに対応
- スケジュール実行、エラー時の自動リトライ機能
使いこなしの難しさ:
GUIで簡単に作れる分、フローが複雑化しやすいという問題は当時と変わりません。命名規則や設計標準がないと、すぐにメンテナンス不能な状態になります。また、複雑な条件分岐やデータ変換ロジックは、GUIだけでは表現しにくく、結局スクリプトを書く必要が出てきます。
文字コード変換機能は改善されていますが、それでも全ての文字を完璧に変換できるわけではありません。特に外字や特殊な異体字に関しては、依然として注意が必要です。
価格面では、オンプレミス版で数百万円から、クラウド版(ASTERIA Warp Core)で月額数万円からとなっており、中小企業にとっては決して安くはありません。導入前に、本当にこのツールが必要か、投資対効果を慎重に検討する必要があります。
ツール2:DataSpider(データスパイダー)
国産のデータ連携ツールとして、ASTERIAと並んで高いシェアを持つ製品です。特に大企業や公共機関での採用実績が豊富です。
便利な機能:
- ドラッグ&ドロップでデータフローを設計
- 1000種類以上のアダプタで、レガシーシステムから最新SaaSまで幅広く対応
- 大量データ処理に強く、並列処理や差分処理が得意
- バージョン管理機能で、フローの変更履歴を追跡可能
使いこなしの難しさ:
機能が豊富な分、学習コストは高めです。初心者が簡単なデータ連携を実装するだけでも、かなりの時間がかかります。また、DataSpider独自の概念(スクリプト、アダプタ、トリガーなど)を理解する必要があり、専任の技術者を確保できない中小企業では運用が難しいかもしれません。
また、バージョン管理機能があるとはいえ、複数人で同時開発する際の排他制御が弱く、大規模プロジェクトでは別途Git等での管理を併用する必要があります。私が経験した「メンテナンス不能」問題を完全に解決するものではなく、やはり設計標準と命名規則の徹底が不可欠です。
ツール3:HULFT Square(ハルフト スクエア)
ファイル転送ツールとして有名なHULFTのクラウド版で、データ連携機能を強化した製品です。オンプレミスとクラウドのハイブリッド環境でのデータ連携に強みがあります。
便利な機能:
- 従来のHULFTとの互換性があり、既存のHULFT資産を活用可能
- オンプレミスとクラウド間のセキュアなデータ転送に強い
- ファイル転送だけでなく、API連携やデータベース連携にも対応
- 月額料金が比較的リーズナブル(月額5万円程度から)
使いこなしの難しさ:
HULFT Squareは、従来のファイル転送中心の思想から抜け切れていない部分があります。複雑なデータ変換やビジネスロジックの実装には向いておらず、あくまで「ファイルやデータを安全に運ぶ」ことが主目的です。
また、GUIは直感的とは言い難く、慣れるまでに時間がかかります。特にエラーメッセージが分かりにくく、トラブル時の原因特定に苦労することがあります。これは私が当時ASTERIAで経験した文字コード問題と同様で、ツールが進化しても、エラーハンドリングの設計は依然として開発者の責任です。
ツール4:Microsoft Power Automate(パワー オートメイト)
Microsoftが提供するクラウドベースの自動化ツールです。データ連携だけでなく、業務プロセス全体の自動化を目指した製品で、Office 365との親和性が高いのが特徴です。
便利な機能:
- Office 365、Dynamics 365、Azure等のMicrosoft製品とシームレスに連携
- 400以上のコネクタで、主要なSaaSやWebサービスと接続可能
- ローコードで、非IT部門でも比較的扱いやすい
- Microsoft 365のライセンスに含まれる場合があり、追加コストなしで使えることも
使いこなしの難しさ:
Power Automateは、簡単な自動化には向いていますが、大規模なデータ連携には限界があります。一度に処理できるデータ量に制限があり、数万件以上のデータを扱う場合は、処理が分割され、実行時間が長くなります。
また、エラーハンドリングやリトライの仕組みが弱く、本番運用で安定稼働させるには工夫が必要です。私が経験した「本番障害」のようなケースでは、Power Automateだけでは対応しきれず、結局Azure Functionsなどのプログラミングが必要になることもあります。
さらに、フロー(Power Automateでは「ワークフロー」と呼ぶ)が増えてくると、やはり管理が煩雑になります。命名規則やフォルダ構成を最初から整備しないと、私が経験したのと同じ「メンテナンス不能」状態に陥るリスクがあります。
ツールは進化しても、本質的な課題は残る
これらの現代ツールは、確かに当時のASTERIAよりも機能が豊富で、使いやすくなっています。特にクラウドSaaSとの連携は、標準コネクタが用意されているため、格段に楽になりました。また、スケジュール実行やエラー通知などの運用機能も充実しています。
しかし、私が1年10ヶ月で経験した3つの失敗パターン、すなわち「仕様書と実態の乖離」「文字コード問題」「メンテナンス性の悪化」は、ツールが進化しても本質的には解決されていません。これらは技術的な問題ではなく、設計とマネジメントの問題だからです。
どんなに優れたツールを導入しても、以下の点を怠れば失敗します:
- 実データの事前確認と仕様書との突合せ
- 文字コード戦略の明確化と例外処理の設計
- 連携設計の標準化と命名規則の徹底
- 定期的なレビューとリファクタリング
逆に言えば、これらをきちんと実施すれば、ツールの選択はそれほど重要ではありません。自社の予算や既存システムとの親和性、担当者のスキルレベルに合わせて選べばよいのです。
データ連携プロジェクトを成功させるための心構え
最後に、1年10ヶ月のプロジェクトを通じて私が学んだ、最も重要な心構えを3つ共有します。
1. 「簡単そう」という思い込みを捨てる
データ連携は、見た目以上に複雑です。「AシステムからBシステムへデータを渡すだけ」というシンプルな説明に騙されてはいけません。その裏には、データ仕様の差異、文字コードの違い、ネットワークの不安定性、タイミングの問題など、無数の落とし穴が潜んでいます。
プロジェクト計画を立てる際は、楽観的な見積もりではなく、十分な余裕を持ったスケジュールを組むべきです。私の経験では、当初見積もりの1.5倍〜2倍の時間がかかるのが普通でした。
2. 「とりあえず動けばいい」を許さない
テスト環境で動いたから本番も大丈夫、という判断は危険です。本番データには、テストでは想定していなかった例外的なケースが必ず含まれています。文字コード、データ型、NULL値、桁あふれなど、あらゆる例外を想定したテストを行うべきです。
また、「とりあえずこの方法で実装して、後で改善しよう」という先送りも禁物です。後で改善する時間は、ほぼ確実に取れません。最初から正しく設計し、標準に従って実装することが、結果的に最も効率的です。
3. 「一人で抱え込まない」
データ連携の設計や実装は、属人化しやすい領域です。特定の担当者だけが全体を把握している状態は、非常に危険です。必ず複数のメンバーで情報共有し、相互レビューを行い、ドキュメントを残すことが重要です。
また、技術的な問題だけでなく、顧客やベンダーとのコミュニケーション問題も一人で抱え込まないことです。仕様の食い違いに気づいたら、すぐに上司やプロジェクトマネージャーに報告し、顧客との認識合わせを行うべきです。問題を隠したまま進めても、後で必ず大きなトラブルになります。
まとめ:失敗から学び、次に活かす
データ連携プロジェクトは、技術的には枯れた領域ですが、だからこそ油断が生まれやすく、失敗のパターンも固定化しています。私が1年10ヶ月かけて学んだ教訓は、決して特殊なケースではなく、多くのデータ連携プロジェクトで起こりうる典型的な問題です。
仕様書と実態の乖離、文字コード問題、メンテナンス性の悪化。これらは、ツールが進化しても本質的には解決されません。しかし、事前の準備と適切な設計、そして継続的なマネジメントによって、十分に防ぐことができます。
もしあなたが今、データ連携プロジェクトに携わっているなら、この記事で紹介した3つの失敗パターンと対策を思い出してください。そして、「簡単そう」という思い込みを捨て、「とりあえず動けばいい」を許さず、「一人で抱え込まない」という心構えで臨んでください。
私自身、当時は数え切れないほどの失敗をしましたが、その一つ一つが貴重な学びとなり、今の実務に活きています。失敗を恐れる必要はありませんが、同じ失敗を繰り返さないために、先人の経験から学ぶことは重要です。この記事が、あなたのデータ連携プロジェクトの成功に少しでも役立てば幸いです。


コメント